
이 포스트에서는 대화형 추천 시스템 (conversational recommender system)에서 핵심적인 요소인 dialogue management에 대해 다룹니다.
추천 시스템과 유저는 서로 상호작용을 주고받는 interactive한 프로세스입니다. 특히, 대화형 추천 시스템에서는 서로 대화를 주고받습니다. 추천 시스템이 유저에게 추천 아이템을 제공할지, 추가 정보를 요구할지, 그 외 잡담을 나눌 지 등 추천 시스템이 유저와 상호작용하는 수단인 대화를 제어하는 것을 dialogue management (DM)라고 부릅니다.
설령, 대화형 추천 시스템일지라도 유저는 마치 검색하듯이 단순히 간단한 질문만으로도 즉각적인 추천 아이템을 얻고 싶을 수 있고, multi-turn 대화를 통해 구체적인 특징을 만족하는 아이템을 얻고 싶을 수 있습니다. 그러나 아이템을 추천받기 위해 대화가 너무 길어지면 유저는 피로감을 느끼겠죠. 또한, 추천된 아이템에 대해 의논하거나 단순 잡담을 시도할 수도 있습니다. 이처럼 대화라는 것은 대단히 복잡한 과정입니다. 따라서 이를 별도로 처리할 필요가 있습니다.
Dialogue Management based on Reinforcement Learning
대화란 것은 보통 여러 번 수행되며 추천 시스템은 유저의 만족도를 높여야합니다. 그렇기 때문에 dialogue management는 연속적인 의사결정 문제 (sequential decision making problem)입니다. 강화학습 (reinforcement learning, RL)은 연속적인 의사결정 문제를 최적화할 수 있습니다. 따라서, 강화학습으로 어떻게 이 문제를 해결할 수 있을 지 알아봅시다.
Markov Decision Process
강화학습을 적용하기 위해서는 markov decision process (MDP)를 정의해야합니다:
- State: 대화 context, 유저 features, 아이템 features, ...
- Action: 추천, 정보 요청, ...
- Reward: 추천 아이템에 대한 feedback (e.g., click-through-rate (CTR), 좋아요, 평점), 유저 query로부터의 긍정/부정 반응, multi-turn 대화로 인한 피로감, 대화 중단, ...
state는 추천 시스템이 action을 결정하기 위해 관찰할 정보들, reward는 유저의 만족도와 관련된 scalar 값입니다.
강화학습은 state가 주어졌을 때 action을 결정하는 policy를 학습합니다. 이 때 feedback으로 reward가 매 time step (i.e., 매 대화 turn)마다 제공되며, 즉각적인 reward가 아닌 cumulative reward를 maximize하도록 학습합니다. 학습을 통해 추천 시스템은 유저 utterance의 의도를 이해하게 됩니다.
Restaurant Recommendation Example
아래는 강화학습을 통해 음식점 추천에 대한 dialogue management를 다룬 실제 예시입니다:
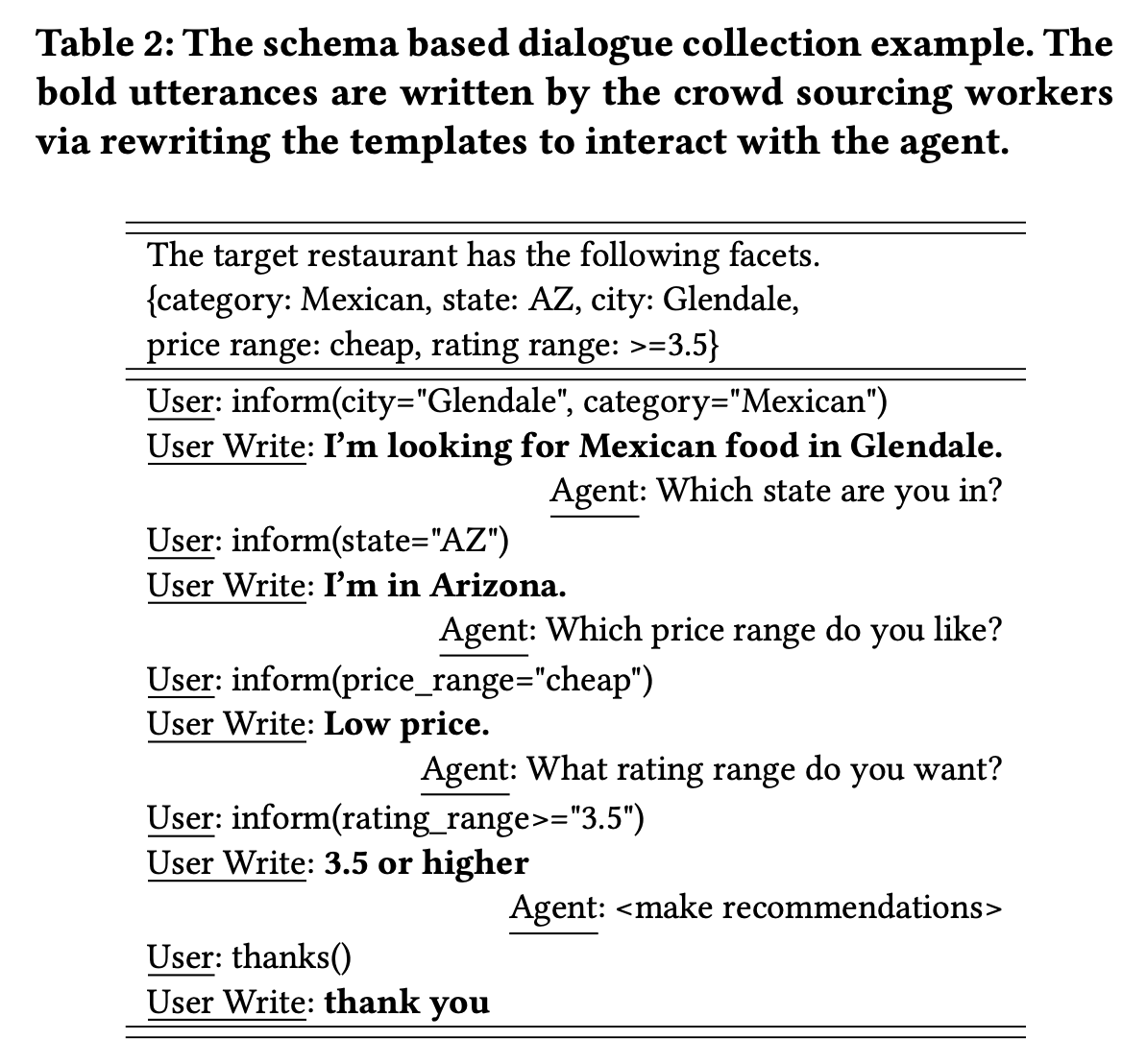
여기서는 비교적 단순하게 모델링했습니다. 추천 시스템이 능동적인 대화를 하기보다는, 단순히 유저의 query에 대해 추천을 제공하거나 부족한 정보를 요청하기만 하는 비교적 수동적인 시스템입니다. 그러나, 이 예시는 강화학습을 통해 dialogue management를 어떻게 다룰 수 있는지를 보여줍니다. 아래는 강화학습을 적용했을 때와 rule-based 모델을 사용했을 때의 유저의 만족도 차이입니다:

MaxEnt는 rule-based 모델이고, CRM은 강화학습 기반 모델입니다. 여기서 중요한 수치는 R과 T입니다. R은 유저의 만족도를, T는 대화 turn을 나타냅니다. MaxEnt를 보면 대화 turn이 늘어날수록 만족도가 늘어남을 알 수 있습니다. 이는 정보를 많이 획득할 수록 더 정확한 추천을 제공할 수 있기 때문입니다. 그러나, MaxEnt Full과 CRM을 비교하면, CRM이 더 적은 대화 turn으로도 높은 만족도를 보여줍니다. 이는 강화학습을 통해 dialogue management를 효과적으로 다룰 수 있음을 보여줍니다. 즉, 더 적은 대화 turn으로 유저의 피로감을 줄이면서 더 나은 추천을 제공할 수 있습니다.