
추천 시스템에 대해 더 자세히 이해하고 싶다면 아래 튜토리얼 코드를 참고하기 바랍니다.
Tutorial Code: DevSlem/recommender-system-rl-tutorial (Github)
추천 시스템 (recommender system)은 유저의 선호도 (preference)에 맞는 아이템을 제공하는 시스템입니다. 이는 유저-아이템 상호작용 히스토리를 고려해 이루어지는데, 추천 시스템이 유저에게 아이템을 제공하면 유저는 이에 대해 피드백 (스킵, 클릭, 구매 등)을 제공합니다. 유튜브, 넷플릭스 등 수 많은 어플리케이션에서 이러한 추천 시스템을 도입하고 있습니다.
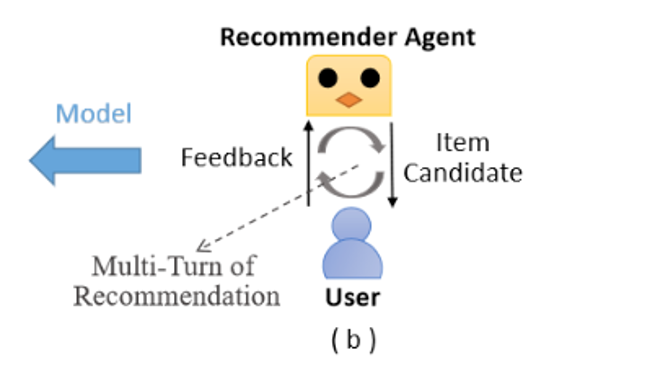
추천 시스템은 머신 러닝 (machine learning)을 통해 구축할 수 있습니다. 지도학습 (supervised learning)과 같은 기존 방법들은 대체적으로 유저와 추천 모델 사이의 상호작용을 무시해 불만족스러운 결과를 내놓습니다. 일반적으로, 추천 시스템은 인터렉티브한 프로세스로 연속적인 의사 결정 문제 (sequential decision making problem)입니다. 따라서 강화학습 (reinforcement learning)을 사용하여 최적화할 수 있습니다. 아래 그림은 지도학습과 강화학습 기반 방법 사이의 성능 비교 테이블입니다.

이 포스트에서는 강화학습으로 추천 시스템을 구축하는 것에 대한 간단한 소개를 하려고 합니다.
Recommdenr System Process
추천 시스템은 크게 두 과정으로 나뉩니다.
- candidate generation
- ranking and recommendation
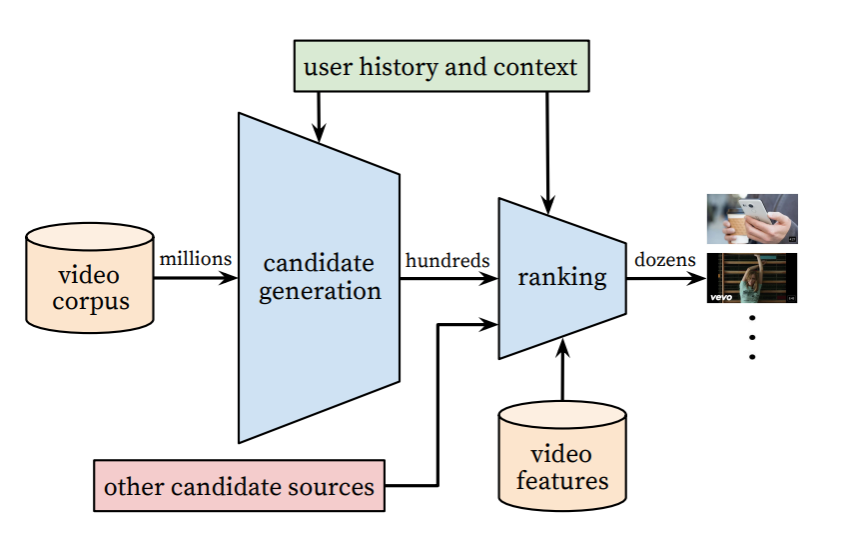
candidate generation은 수많은 아이템 중 일부분을 추출하는 과정입니다. 너무 많은 아이템을 모델에 입력하는 것은 비효율적이기 때문에 사전에 걸러내는 작업입니다. 이 때 후보 아이템 set을 document라고 부릅니다. ranking and recommendation은 document 아이템 중에서 실제 유저에게 추천할 아이템을 선택하는 과정입니다. 여기에 머신 러닝과 같은 기법이 사용됩니다. document로부터 선택된 아이템 set을 slate라고 부릅니다.
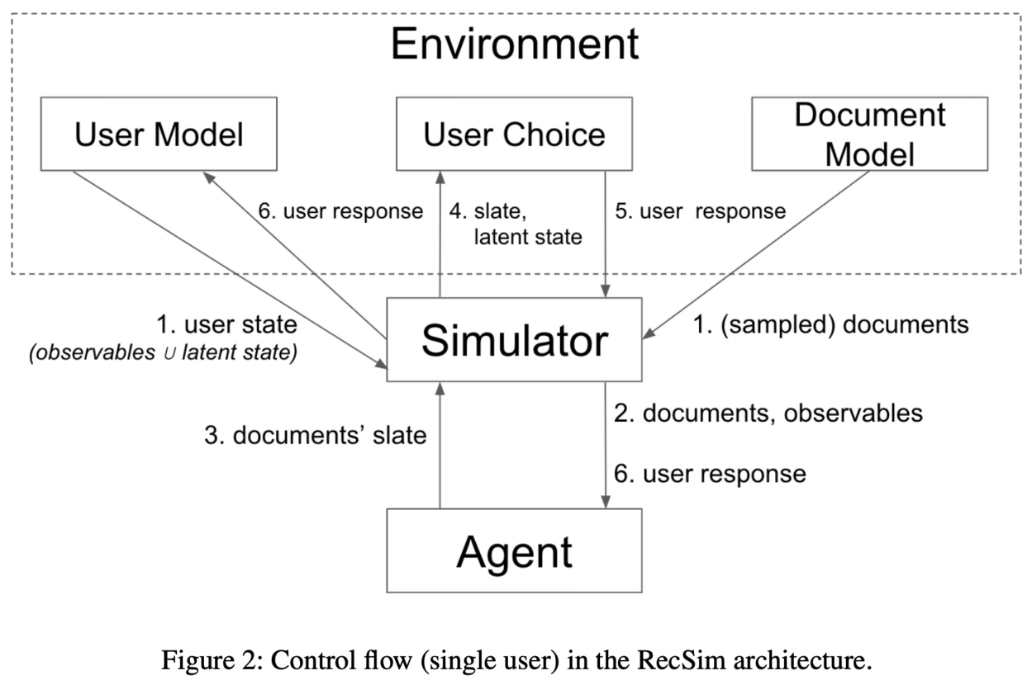
Google RecSim은 유저와의 연속적인 상호작용을 지원하는 추천 시스템에 대한 시뮬레이션 environment로, youtube 추천 알고리즘을 위해 개발되었습니다. 아래는 RecSim 아키텍쳐를 나타내는 그림으로 지금까지 설명한 내용을 한번에 보여주고 있습니다.
자, 이제 toy 문제를 보고 왜 강화학습이 유용한지 알아봅시다.
Problem: Recommend Items based on Sweetness
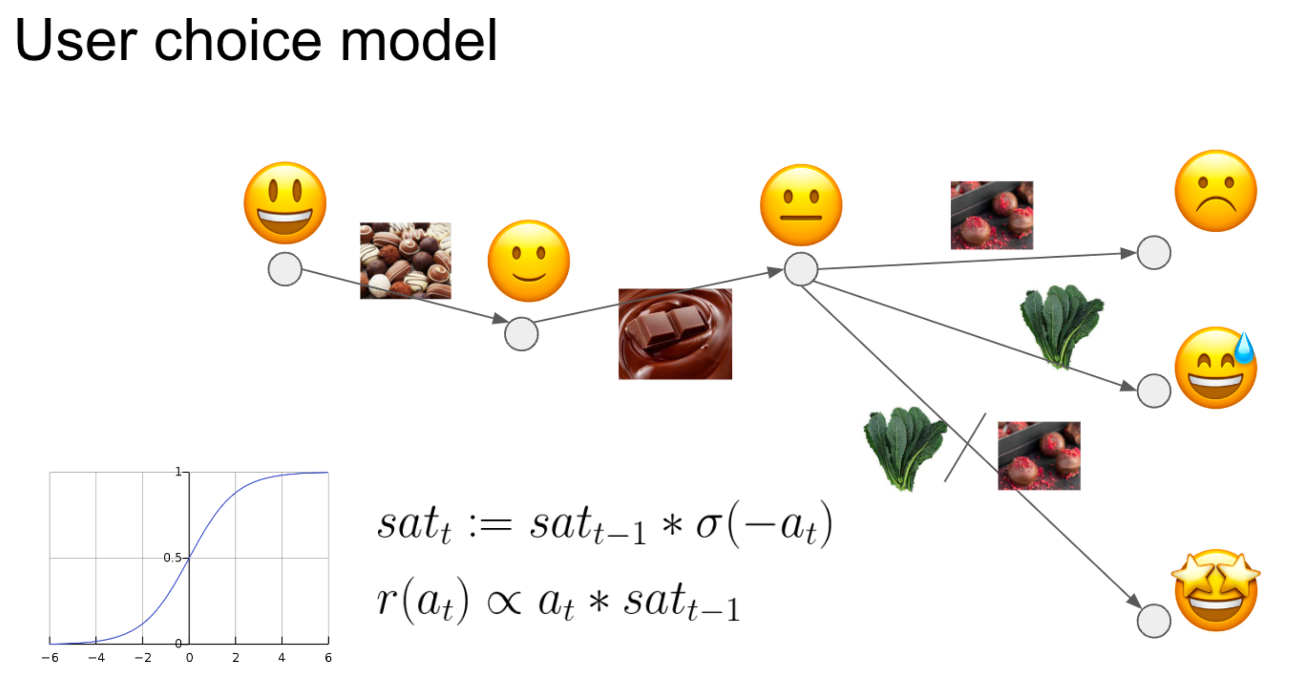
초콜릿과 케일 (채소)이 여러 개 있습니다. 우리는 초콜릿과 케일 중 어떤 것을 추천해야 유저가 만족할까를 고민하고 있습니다. 초콜릿은 단 맛이고, 케일은 쓴 맛이기 때문에 초콜릿과 케일을 달콤함 (sweetness)로 나타낼 수 있습니다. 여기서는 단순함을 위해 달콤함만 고려합시다. 유저들은 대체적으로 쓴 음식보다는 달콤한 음식을 선호할 것입니다. 우리가 생각해볼 수 있는 방법은 달콤한 음식만 추천하는 것입니다. 그러나 달콤한 음식만 추천하다보면 유저들은 점점 만족스러워하지 않을 것입니다. 왜냐하면 자신의 건강 역시 생각하기 떄문이죠. 따라서 유저들은 달콤한 음식보다는 건강에 좋은 달콤하지 않은 음식을 점점 더 선호하게 될 가능성이 있습니다. 그러나 대체적으로 달콤한 음식을 선호하는 유저들이 지속적으로 쓴 음식만 추천 받는다면 역시 불만족스럽겠죠. 이러한 요소들을 종합하면 우리의 가설은 다음과 같습니다: 유저들은 대체적으로 달콤한 음식을 선호하지만, 시간이 지나면서 점점 달콤한 음식의 선호도가 내려가기 때문에 중간 중간 달콥하지 않은 음식도 추천 받길 원한다.
Reinforcement Learning
위 문제를 강화학습으로 학습하기 위해 추천 시스템의 요소들을 잘 정의해야합니다. 추천 시스템의 궁극적인 목적은 유저의 engagement를 maximize하는 것입니다.
Objective: Maximize user's engagement.
여기서 engagment란 단어가 다소 모호할 수 있습니다. engagement란 추천된 아이템에 대한 상호작용이나 유저의 행동으로, 유저의 흥미나 관심을 얼마나 효과적으로 끌고 있는지를 나타내는 측정값입니다. 예를 들면, 추천된 동영상을 시청한 시간 정도 입니다.
이제 다음을 정의해봅시다:
- Observation: sweetness of 20 items
- Action: recommends 1 item
- Reward: represents the engagement
observation은 추천 모델이 관찰하는 정보입니다. 여기서는 단순함을 위해 유저 feature는 고려하지 않습니다. 그러나 유저 feature는 실제로 매우 중요합니다. 예를 들어 성별을 고려 시, 상대적으로 여성이 남성보다 달콤한 음식을 선호하므로 이는 추천 시 중요한 feature가 될 수 있습니다.
Baselines
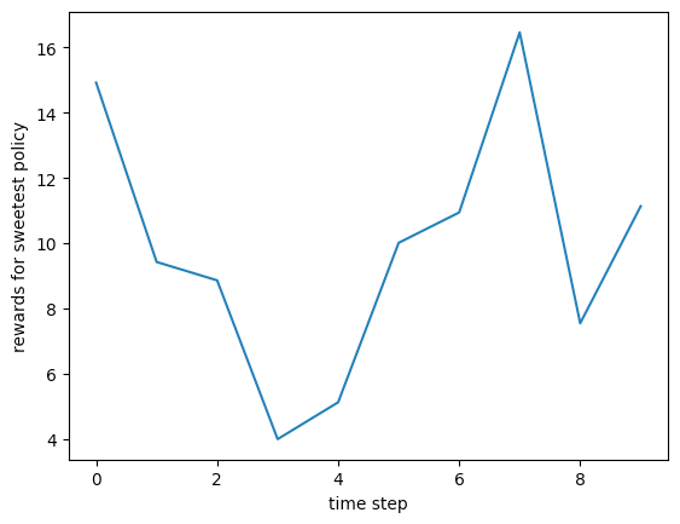
먼저, baseline으로 가장 달콤한 아이템만 추천하는 sweetest policy와 랜덤하게 추천하는 random policy를 사용하겠습니다. 아래는 두 베이스라인의 시간에 따른 reward 변화입니다.
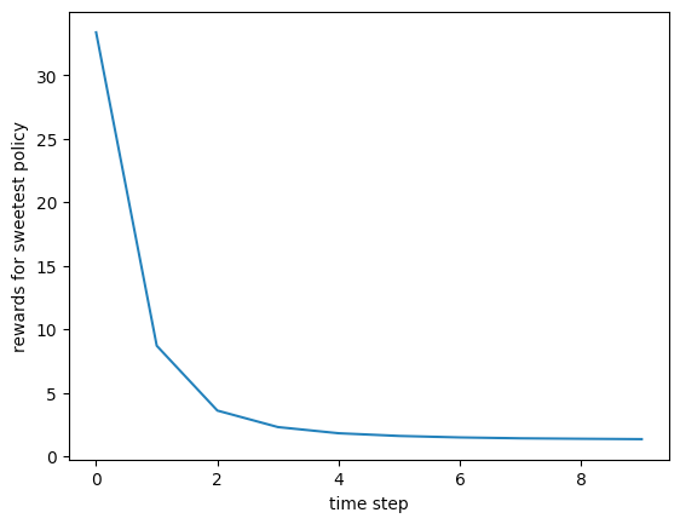
- sweetest policy cumulative reward: 56.93+/-1.44
- random policy cumulative reward: 98.41+/-24.32
유저들은 대체적으로 달콤한 음식을 선호하지만, 시간이 지나면서 점점 달콤한 음식의 선호도가 내려감을 알 수 있습니다. cumulative reward는 모든 time step동안 획득한 reward의 총합입니다.
RL Performance
multi-armed bandit (MAB)는 기존에 추천 시스템에 많이 사용되던 방법입니다. short-term RL은 즉각적인 reward만 고려하는 강화학습 방법으로, MAB와 유사한 속성을 지니고 있습니다. 따라서 short-term RL을 통해 MAB의 문제점을 확인할 수 있습니다.
반대로 long-term RL은 future reward도 고려해 학습하는 방법입니다. 연속적인 의사 결정 문제에서 future reward에 대한 고려는 매우 중요합니다. 현재 선택한 action이 future reward에 영향을 미치기 때문입니다.
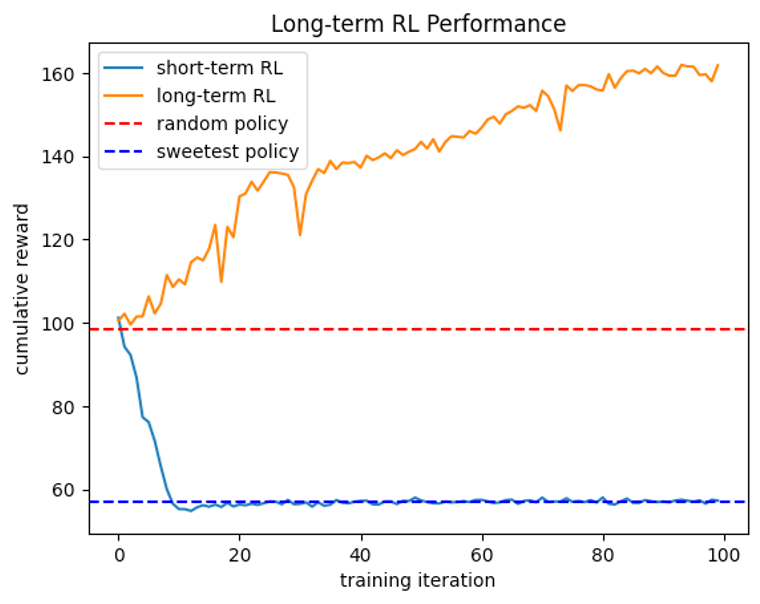
- short-term RL: discount factor = 0
- long-term RL: discount factor = 0.99
short-term RL은 학습 결과 sweetest policy와 유사해집니다. 이는 너무 당연한게, 유저들은 대체적으로 달콤한 음식을 선호하기 때문에 즉각적인 reward가 높기 때문입니다. long-term RL은 future reward도 고려하기 때문에 결과적으로 cumulative reward가 가장 높습니다.
References
[1] Anyscale "ACM RecSys 2022 Tutorial" (Github).
[2] Ie, Eugene, et al. "Recsim: A configurable simulation platform for recommender systems. " arXiv preprint arXiv:1909.04847 (2019).
[3] Lin, Yuanguo, et al. "A survey on reinforcement learning for recommender systems." IEEE Transactions on Neural Networks and Learning Systems (2023).
[4] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.