
이 포스트에서는 대화형 추천 시스템 (conversational recommender system)을 구축하기 위한 전반적인 과정과, 유저의 utterance와 같은 텍스트 데이터를 어떻게 처리할 것인가에 대해 간략히 다룹니다.
유저의 utterance로부터 대화형 추천 시스템 구축은 자연어 처리 (natural language process), 추천 알고리즘, 유저 context에 대한 조합을 요구하는 복잡한 태스크입니다. 이를 step-by-step으로 알아봅시다:
- Data Collection:
- 이름, 위치, 타입 (e.g., bar, cafe, fine dining), 분위기 (e.g., quiet, lively), 음식 종류, 평점, 리뷰 등의 디테일한 정보를 포함하는 음식점 데이터셋을 모으는 걸로 시작합니다.
- 가능한, 유저의 선호도와 행동 데이터 (e.g., 이전에 방문한 음식점, 평점)를 모을 수 있으면 좋습니다.
- Text Preprocessing:
- 유저의 utterance을 처리하기 위해 NLP 기법을 사용합니다:
- Tokenization
- Lowercasing
- Removing stop words
- Lemmatization or stemming
- 유저의 utterance을 처리하기 위해 NLP 기법을 사용합니다:
- Intent and Entity Recognition:
- utterance로부터 유저의 의도 (e.g., "find", "recommend", "search")를 추출합니다. 이때, intent recognition 모델을 사용합니다.
- entity나 keyword (e.g., "quiet", "bar", "seafood")를 entity recognition이나 keyward extraction 기법을 사용해 추출합니다.
- Contextual Understanding:
- 시스템이 stateful하다면, 유저 context를 이해하기 위해 과거 상호작용들을 기억합니다. 이는 추천을 더 잘 정제할 수 있습니다. 예를 들어, 유저가 이전에 비건이라고 언급했다면, 고기집은 적절치 않은 추천입니다.
- 지역기반 서비스를 구축합니다. 유저가 특별히 다른 장소를 언급하지 않았다면, 유저 근처의 음식점 추천합니다.
- Candidate Generation:
- collaborative filtering이나 content-based filtering과 같은 전통적인 추천 알고리즘을 사용해 candidate list를 생성합니다.
- 추출된 entity를 바탕으로 이 리스트를 필터링합니다. 예를 들어, "quiet"와 "bar"가 entity라면, "quiet"한 attribute를 가진 bar만을 선택합니다.
- 유저의 행동 데이터가 있다면, 추천 리스트를 re-rank해 우선순위를 조정합니다. 예를 들어, 유저가 이탈리안 음식점을 자주 방문했다면, 이러한 음식점을 높은 우선순위에 둘 수 있습니다.
- Hybrid Approach:
- 추천 퀄리티를 높이기 위해 여러개의 추천 알고리즘을 결합할 수도 있습니다. 예를 들어, collaborative와 content-filtering을 결합하거나 딥러닝 기반 모델을 결합할 수 있습니다.
- Feedback Loop:
- 유저가 추천된 아이템들에 피드백을 제공하도록 합니다. explicit (e.g., ratings, likes)하거나 implicit (e.g., click-through rates, time spent)한 피드백들이 있습니다.
- 이러한 피드백을 사용해 지속적으로 추천 프로세스를 개선할 수 있습니다.
- Post-Processing:
- 유저에게 적절한 수의 추천 아이템을 제공합니다 (e.g., top 5 or top 10).
- 관련도, rating, 인기도와 같은 어떠한 metric을 사용해 추천된 아이템을 정렬합니다.
- UI/UX Considerations:
- 대화형 방식을 통해 context와 함께 추천 아이템을 제공합니다. 예를 들어, "근처 조용한 술집을 찾았어요:".
- 유저가 추천 시스템의 query를 조정하거나 추가 질문을 할 수 있게 합니다. 예를 들어, "이 중 실외석이 있는 곳이 있니?".
- Evaluation and Continuous Learning:
- 주기적으로 추천 시스템의 performance를 평가합니다. A/B testing과 같은 방법이 있습니다.
- 데이터와 피드백을 더 많이 수집하고, 추천 모델을 개선합니다.
이 중 텍스트 데이터를 처리하는 방법에 대해 집중적으로 다뤄보겠습니다.
How to Extract Features from Text Data
유저의 utterance와 같은 텍스트 데이터로부터 추천 시스템에 사용할 feature를 추출할 때 크게 2가지 방법으로 처리할 수 있습니다: named entity recognition, keyword extraction. 두 방법은 비슷하면서도 다릅니다.
Named Entity Recognition
named entity recognition (NER)은 일종의 tagging 작업입니다. 어떤 텍스트로부터 entity를 사전에 정의된 카테고리로 분류하는 정보 추출 작업입니다. 카테고리 예시로 음식 타입, 분위기, 위치 등이 있습니다. NER 모델은 labeled data로부터 학습됩니다. 각 문장 내 단어는 상응하는 entity 타입으로 태그되어있습니다. entity는 유스케이스에 따라 다르게 정의됩니다. 아래 그림에서 entity로 'Name', 'Date', 'Designation', 'Subject"가 사전에 정의되어있는걸 확인할 수 있습니다.
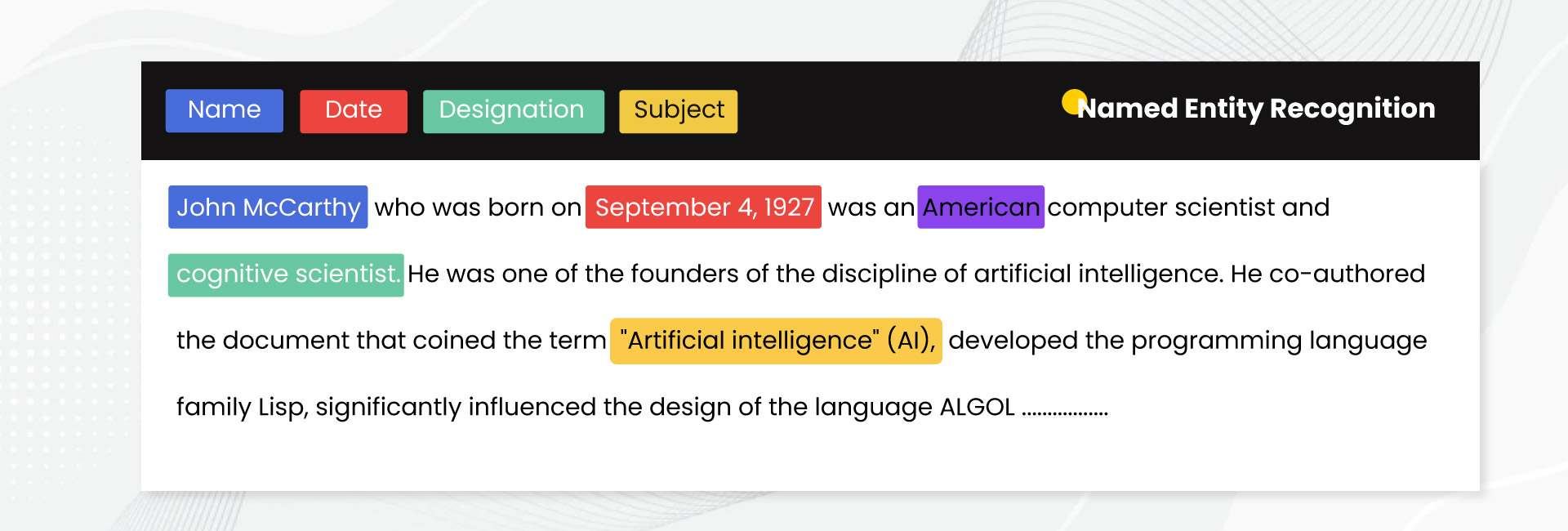
Usage in candidate generation:
- 음식점 추천 시스템 맥락에서, NER은 유저 uterrance로부터 특정 entity를 식별합니다. 예를 들어, "시카고 내 이탈리안 음식점을 원해"라는 문장에서, "이탈리안"은 '음식 타입', "시카고"는 '위치'로 인식됩니다.
- candidate generation은 식별된 entity에 대응하는 음식점을 찾습니다.
Keyword Extraction
keyward extraction은 거대한 텍스트 조각으로부터 관련된 용어를 식별 및 추출하는 작업입니다. 이는 entity가 사전에 정의되어있는가에 관계 없이 수행되며, 일종의 요약과 유사합니다.
Usage in candidate generation:
- "quiet", "rooftop", "seafood"와 같은 keyword를 유저의 utterance로부터 추출합니다.
- 이러한 keyword들은 음식점의 attribute, 태그, 리뷰 등과 매칭됩니다.
Our Case
추천 시스템 구축에는 NER이 조금 더 적합하다고 판단됩니다. 그러나, NER은 labeled data로부터의 학습이 필요하기 때문에, 데이터셋을 별도로 구축하고 학습까지 해야하는 문제가 있습니다.
GPT는 자연어에 대해 충분히 이해하고 추론할 수 있는 능력을 가지고 있습니다. GPT를 활용한다면 NER 작업을 쉽게 할 수 있을 거라 판단됩니다:
- 음식점에 대한 entity를 사전에 잘 정의.
- GPT에게 entity를 추출해달라고 프롬프팅.
- 유저 utterance 또는 아이템 description 입력.
- 추출된 entity를 추천 모델에 입력.
실제, 간이 테스트 결과 GPT-3.5, GPT-4 모두 훌륭한 결과를 내놓았습니다.